Prioritize with Python

My last prioritization meeting
The hardest part of building products isn’t deciding what to build. It’s deciding what to build first.
Every product manager faces the reality of unlimited ideas, constrained resources, and stakeholders asking for clarity on what’s coming next. The usual response is a flurry of prioritization meetings and endless debates about what matters most and how to sequence it.
But here’s what I’ve learned after years of wrestling with roadmaps - the thinking part and the sequencing part are fundamentally different problems. When you conflate them, you create unnecessary complexity and yield worse decisions.
The Hidden Structure of Prioritization
Most product teams approach prioritization as a single, monolithic problem. This is a mistake. The process naturally breaks into two distinct phases, each requiring different mental models:
Ranking answers the question of what should we build, all constraints aside.
Sequencing determines the optimal order given our priorities and dependencies.
The first is an art. The second is a science.
Ranking requires judgment, intuition, and deep understanding of customer needs. It’s where product sense matters most. You can’t automate good judgment any more than you can automate taste.
But sequencing is mechanical. Once you know what you want to build and understand your constraints and dependencies, determining the optimal order follows predictable rules. Dependencies create sequences, resource constraints create trade-offs, and time pressure creates urgency.
The problem is that most teams manually recalculate sequences every time priorities shift. This creates two problems - it’s time-consuming, and it’s error-prone. Every manual recalculation becomes an opportunity for sub-optimization.
Automating the Mechanical
After watching too many teams struggle with this problem, I built a simple Python script that automates the sequencing process. Feed it your ranked priorities and dependency relationships, and it outputs the optimal development sequence.
The algorithm is straightforward - prioritize high-value, low-dependency features first. When dependencies exist, sequence them appropriately. When multiple features have equal priority and dependency profiles, the original ranking becomes the tiebreaker.
The script reads a CSV file containing features, their relative priorities, and dependencies between them. It then applies a consistent set of rules to determine the optimal sequence.
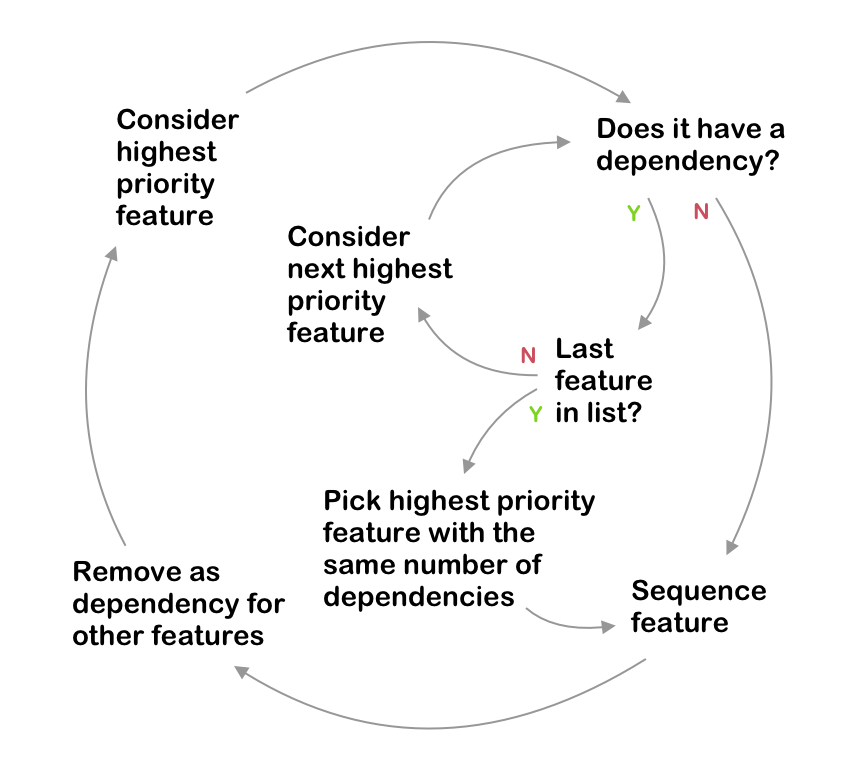
The script’s sequencing logic
The beauty lies not in the complexity of the algorithm (it’s quite simple) but in its consistency. Humans make different decisions based on mood, recent conversations, and cognitive biases. The script makes the same decision every time when given the same inputs.
The sequencing algorithm in action
The output includes two critical pieces of information - the optimal sequence and how much each feature’s position changed from the original ranking. This change metric reveals something important. It shows where dependencies and constraints significantly alter your intuitive ordering.
The Implementation
The script requires basic Python knowledge and takes less than five minutes to run. You’ll need:
- →Python 3 with numpy and pandas
- →A CSV file with your features, priorities, and dependencies
- →Basic command line familiarity
If you lack technical skills, you have two options. First, stick with manual sequencing using the flowchart above (it’s perfectly workable for smaller roadmaps). Second, invest time in learning basic programming skills. This investment pays dividends far beyond roadmap management.
The execution is simple:
- →Save the script as
prioritize.py - →Create your input CSV with features, priorities, and dependencies
- →Run:
python3 prioritize.py --source your_features.csv - →Review the optimized sequence
The script outputs results to the command line by default, but you can save to a new CSV file using the --output flag.
Beyond Efficiency
This approach delivers more than time savings. It surfaces hidden insights about your roadmap’s structure. When the script significantly reorders your intuitive sequence, it’s highlighting dependency chains you may have missed or underestimated.
It also enables rapid scenario planning. Change a few priority scores or add new dependencies, rerun the script, and see how your roadmap shifts. This makes quarterly planning discussions more productive. Instead of debating sequences, you can focus on the harder questions of relative priority and strategic direction.
The script isn’t perfect. It doesn’t account for varying development times or team capacity constraints, and it assumes features can’t be parallelized. Real roadmaps are messier than CSV files.
But perfect is the enemy of good. The script handles 80% of sequencing decisions automatically, freeing you to focus on the 20% that require human judgment. In product management, this is a significant win.
The code is below. Use it, modify it, improve it. Your roadmap (and your sanity) will thank you.
The Script
import pandas as pd
import numpy as np
import argparse
def main():
# Set up the command line parser
parser = argparse.ArgumentParser(description="Prioritize features based on dependencies")
parser.add_argument("-i", "--input", help="Source CSV file", required=True)
parser.add_argument("-o", "--output", help="Output CSV file", required=False)
args = parser.parse_args()
# Load, process, and output the feature list
df = load_feature_list(args.input)
df = process_feature_list(df)
output_feature_list(df, args.output)
def load_feature_list(filename):
"""Load features from CSV and prepare for processing"""
df = pd.read_csv(filename)
df['sorted_priority'] = np.nan
df['dependency_count'] = np.nan
# Convert dependency strings to lists
df['temp_dependencies'] = df['dependencies'].apply(split_dependencies)
return df
def process_feature_list(df):
"""Process features to determine optimal sequence"""
remaining_features = len(df)
while remaining_features > df['sorted_priority'].count():
# Calculate dependency counts and sort
df['dependency_count'] = df['temp_dependencies'].apply(len)
df.sort_values(by=['sorted_priority', 'dependency_count', 'priority'],
inplace=True, na_position='first')
df.reset_index(drop=True, inplace=True)
# Assign next priority to the best available feature
df.at[0, 'sorted_priority'] = get_next_priority(df)
# Remove completed feature from other dependencies
completed_feature = df.at[0, 'id']
df = remove_from_dependencies(df, completed_feature)
return df
def output_feature_list(df, output_file=None):
"""Output the prioritized feature list"""
# Calculate priority changes
df['priority_change'] = df['priority'] - df['sorted_priority']
# Sort for final output
df.sort_values(by=['sorted_priority'], inplace=True)
# Select relevant columns
output_df = df[['id', 'name', 'sorted_priority', 'priority',
'dependencies', 'priority_change']].copy()
print(output_df.to_string(index=False))
if output_file:
output_df.to_csv(output_file, index=False)
print(f"\nResults saved to {output_file}")
def split_dependencies(dependency_string):
"""Convert dependency string to list"""
if pd.isnull(dependency_string):
return []
if isinstance(dependency_string, str):
return [dep.strip() for dep in dependency_string.split(',') if dep.strip()]
return []
def get_next_priority(df):
"""Get the next available priority number"""
max_priority = df['sorted_priority'].max()
return 1 if pd.isnull(max_priority) else max_priority + 1
def remove_from_dependencies(df, completed_feature):
"""Remove completed feature from all dependency lists"""
for idx in range(len(df)):
current_deps = df.at[idx, 'temp_dependencies']
df.at[idx, 'temp_dependencies'] = [dep for dep in current_deps
if dep != completed_feature]
return df
if __name__ == "__main__":
main()Note: This is a simplified model. It doesn’t account for development time variations or parallel work streams. If the output doesn’t align with your team’s constraints, adapt accordingly. The goal is progress, not perfection.