System dynamics + backlog management
Managing technology projects is full of hard decisions and imperfect information.
- →Should you prioritize speed or quality?
- →Should you fix tech debt or focus on new features?
- →Should you build or buy?
These aren’t simple choices and they’re not supposed to be. A decision in one place creates consequences somewhere else. Sometimes immediately, sometimes months later, and almost always unexpectedly.
Most teams navigate these decisions using gut feel. Or worse, Best Practices™️.
But those approaches are half measures. They tell you what to do. They never explain why.
The communication gap nobody talks about
Referencing Best Practices™️ is a cheap shortcut.
It’s the business equivalent of “because I told you so.” It shuts out the people who need to understand your decisions most. They make everything feel arbitrary and turns collaboration into compliance.
But some companies don’t tolerate these cop-outs. They push their teams to actually understand each other. When that happens, trust replaces suspicion and transparency replaces politics. Everything just works.
The communication gap between technical and nontechnical teams is massive. And growing. It drains more energy than any bad architecture decision ever could.
Fix this gap and you’ll accomplish more than a thousand Agile workshops ever will.
I’ve tried bridging it many ways. Most failed. One worked brilliantly.
It comes from system dynamics.
System dynamics: the lost art of seeing
Jay Forrester was an electrical engineer who found himself working in MIT’s business school in the 1950s. It was an strange career transition but it produced extraordinary results.
Forrester took the scientific methods he knew from engineering and applied them to business problems. Working with large companies on their most challenging issues, he discovered something that changed how we think about organizations: most business problems aren’t caused by external factors like competition or market conditions.
They’re caused by the company’s own internal structure.
The causes and effects, feedback loops, incentives, and relationships within organizations were largely invisible to the people running them. But they were incredibly powerful. And once you could see them clearly, they became fixable.
Forrester found that well-intentioned policies were often creating the very problems they were designed to solve. Once managers could see these hidden dynamics, they changed their approach and problems that had been so persistent simply disappeared.
This systematic approach, and the field of study they helped create, became known as System Dynamics.
How it actually works
System Dynamics rests on two principles that are simple when considered separately but become powerful when combined.
The first principle is straightforward: visual representation beats verbal description. Drawings tell stories better than docs.
The second principle comes from Forrester’s engineering background. In engineering, when real-world experiments are expensive, difficult, or time-consuming to run, you simulate them mathematically. You can see how systems evolve over time, find the leverage points within them, and test different interventions.
Forrester’s key insight was to combine these approaches. When you create visual models that move through time, you suddenly see how systems breathe. You can identify where they break down and can start to understand how to fix them.
For any system with feedback loops - businesses, software teams, your own habits - this is gold.
Modeling how software teams really work
Here’s a model every developer will recognize. It shows how code quality, refactoring, and waste determine what a team can actually ship and maintain.
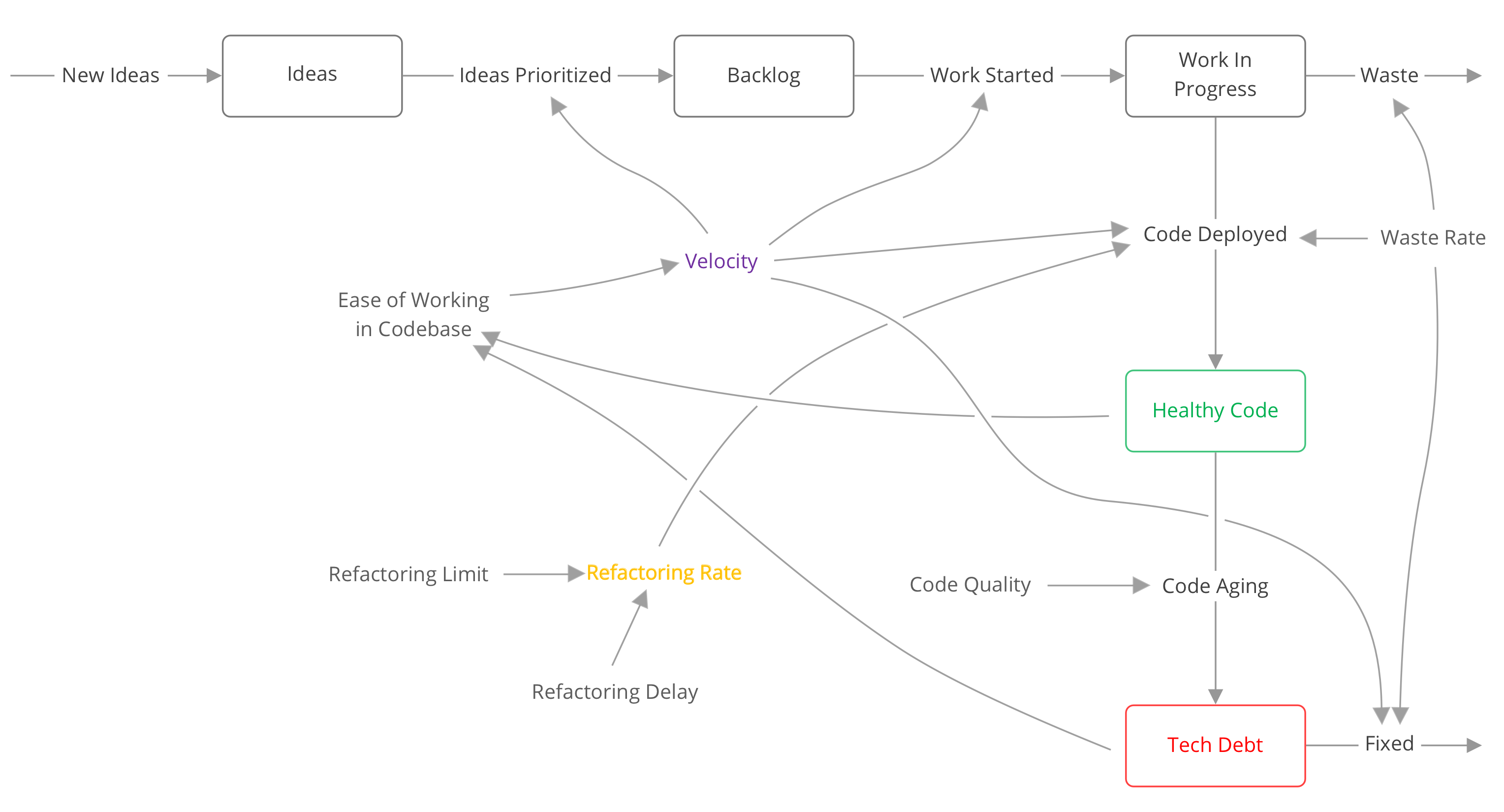
Every model is wrong but some are useful. This model isn’t perfect, but it’s perfect for our purposes.
Watch what happens when we run it.
The natural rhythm
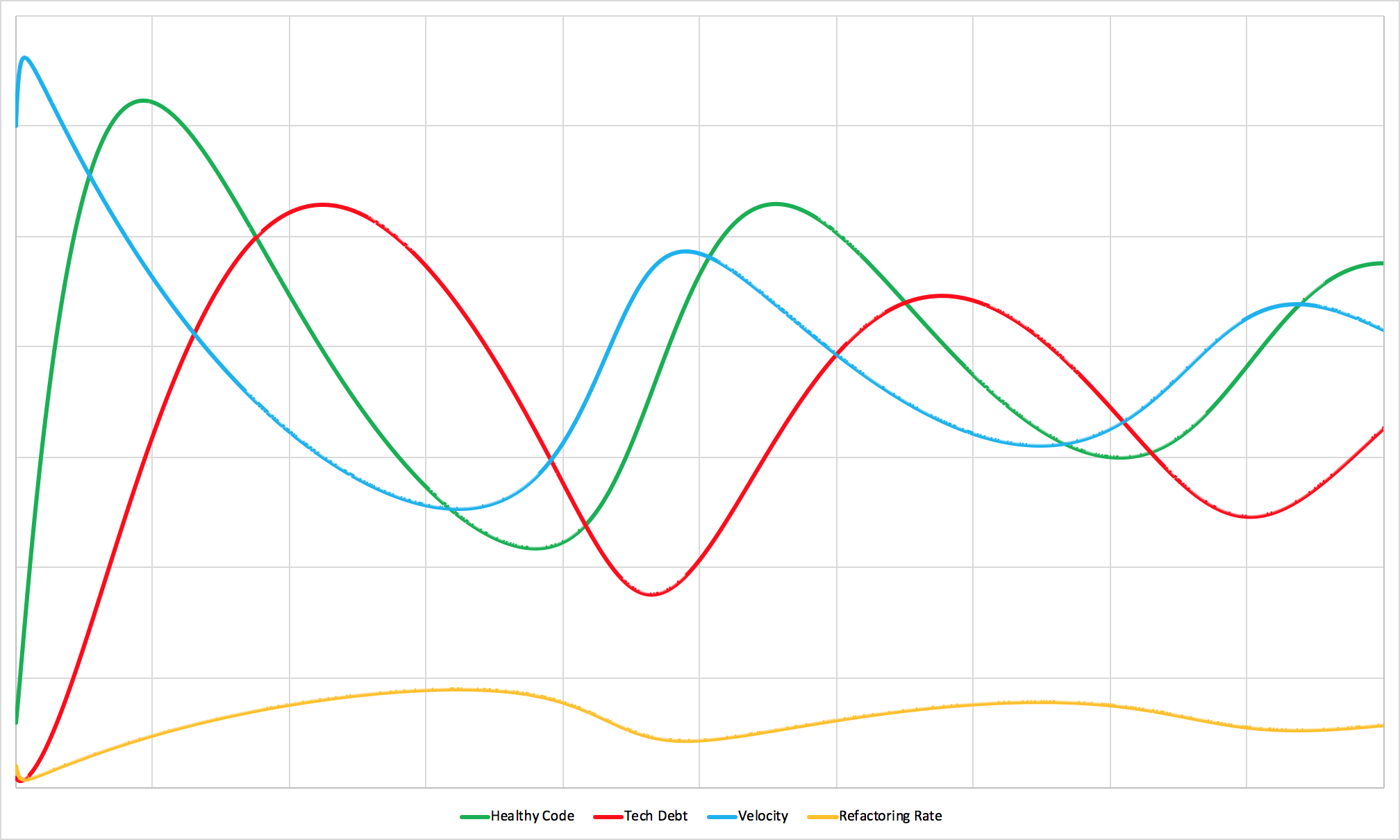
A healthy team finding its natural balance.
Let’s start with a scenario most teams would envy: a small, manageable codebase with very little technical debt. In this environment, developers can work efficiently and ship features quickly. The amount of healthy, working code grows at an impressive rate.
But success in software development carries within it the seeds of its own eventual slowdown. Those early ideas and implementations that seemed so clever at the time? Some of them turn out to be less than ideal. Quick implementations that got features out the door become tomorrow’s constraints. What was once healthy, well-functioning code gradually ages into technical debt.
As the ratio of technical debt to healthy code increases, the team’s velocity naturally begins to slow down. This isn’t a failure of the team - it’s physics. Good teams recognize this pattern quickly and start allocating more of their time to addressing the accumulated issues.
Paying down technical debt takes time, and the process can feel frustrating because healthy code continues to age even while you’re working to fix existing problems. But progress does come. The codebase becomes easier to work with again, velocity increases, and the team has more bandwidth to spend on shipping new features. Then they release the next wave of functionality, debt accumulates again, and the system starts the cycle over.
This is the natural rhythm that healthy teams discover over time. Sometimes they’re shipping features furiously. Sometimes they need to slow down and rebuild their foundations. It’s a lot like breathing - there’s a natural ebb and flow that keeps the system healthy.
External shocks can certainly disrupt this pattern. New technologies, regulatory changes, competitive pressures, or changes in business strategy can all force teams out of their natural rhythm. But when left to their own devices, this cycle emerges organically in teams that have established:
- →High code quality standards
- →Low priority thrash and context switching
- →The authority to balance new feature development with refactoring work
When any of these inputs change, the entire system transforms in response.
When quality drops
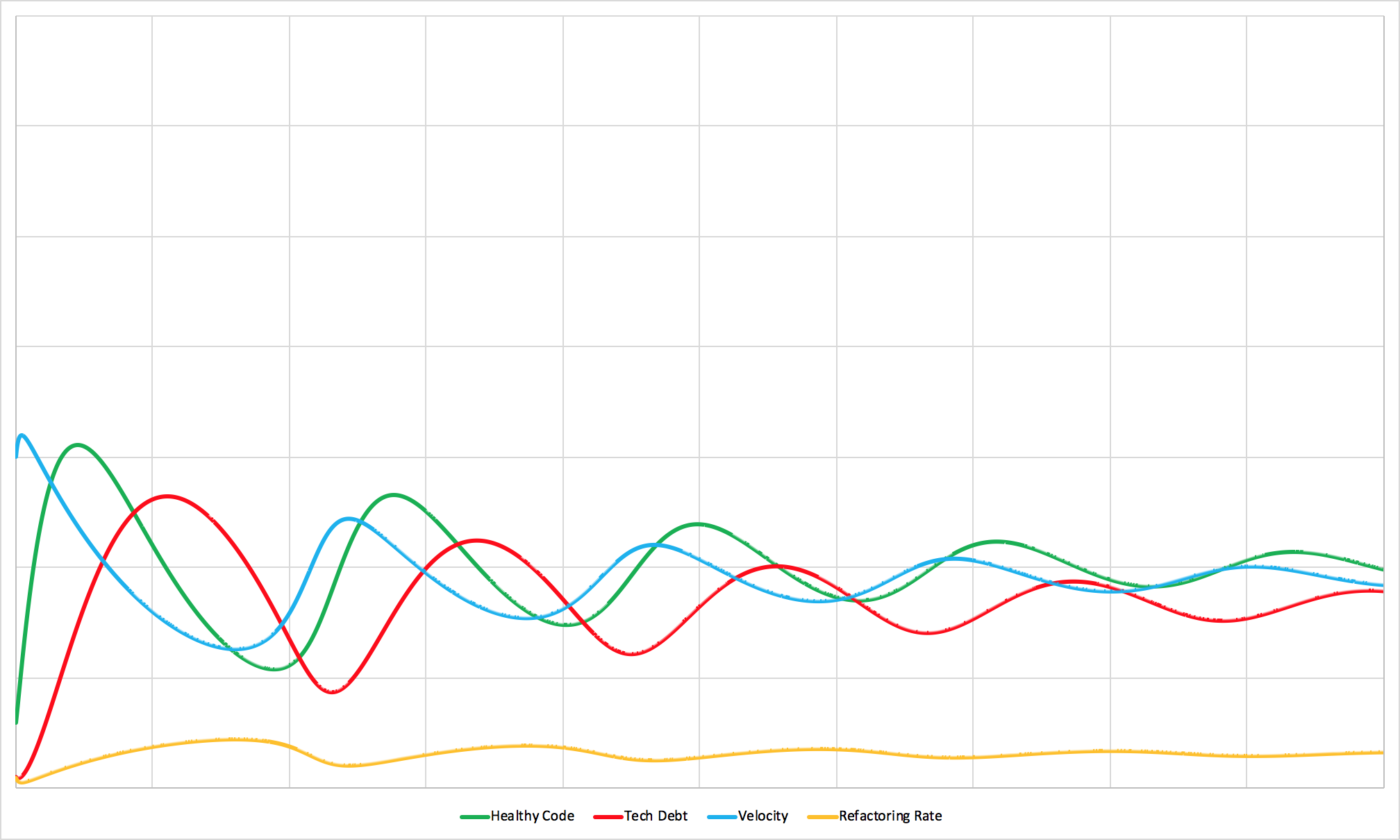
Same team. Lower code quality. Dramatic differences.
Code quality is a major determinant of how fast healthy code becomes technical debt. Lower quality code ages much faster than higher quality code does.
When you compare this simulation to the healthy team, two things become immediately apparent:
First, the cycles accelerate dramatically. This makes intuitive sense - if code degrades faster, you hit the productivity wall sooner. You have to stop and address debt more frequently, which means constantly switching contexts between building new features and fixing existing problems.
But there’s a second, more subtle effect: the team maintains less overall code. Between the faster decay rate and the constant context switching, they simply can’t support as large a codebase.
When you extrapolate this to the company level, the implications are huge: organizations with low code quality standards need more development teams to support fewer features than organizations with higher standards.
If your company has large engineering teams but struggles to ship new features consistently, your code quality standards might be the highest-leverage place to focus your improvement efforts.
The priority shuffle
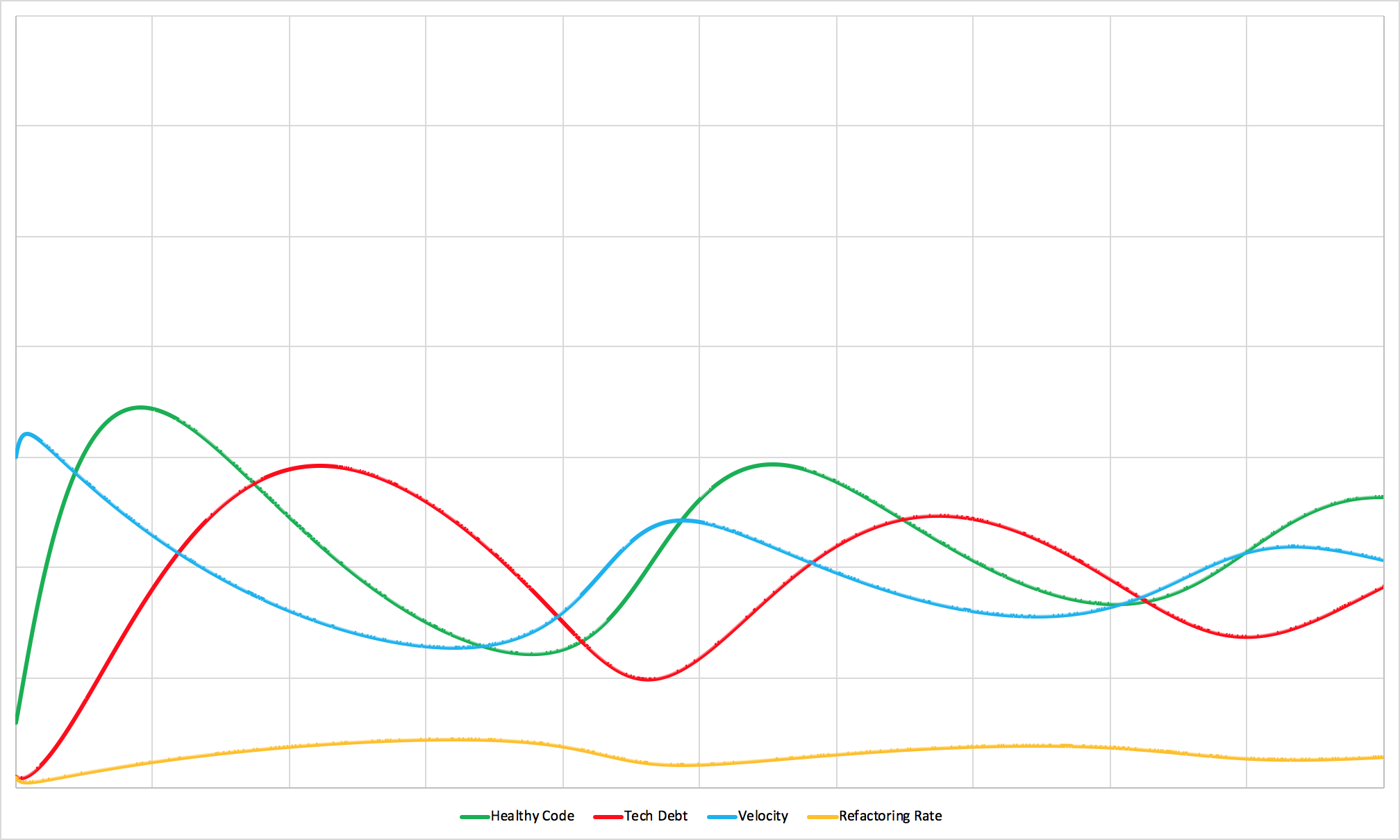
A team drowning in changing requirements.
Building software takes time, and while it’s being built, priorities inevitably shift. Work that was once important gets thrown out, shelved for later, or completely redone.
Some level of change is natural and healthy. Too much change creates thrash and wasted effort. Too little change means spending months building the wrong thing entirely.
This dynamic is exactly why Agile methodologies work so well - they emphasize small pieces of work, frequent releases, and minimal waste when priorities inevitably shift.
Both extremes - too much change and too little change - create waste, just from different causes. The result is the same: development effort that never reaches production and never delivers value to users.
The important thing to understand is that waste doesn’t reduce the total amount of work your team does. It only reduces the amount of useful work that actually ships. And it affects both new feature development and technical debt refactoring equally.
If you look at the simulation, you’ll notice that the natural rhythm of the team stays largely the same. But the amplitude shrinks dramatically. The team ships much less despite putting in the same effort.
The math is brutal but simple: a five-person team with 40% wasted work is functionally equivalent to a three-person team.
How often should priorities change? It depends on your context. Startups still searching for product-market fit need much more flexibility than infrastructure teams at large corporations. But if you find yourself constantly throwing away work or always working on things you know aren’t the most valuable, it’s a smell that ou should probably reconsider your planning process.
The danger of delays
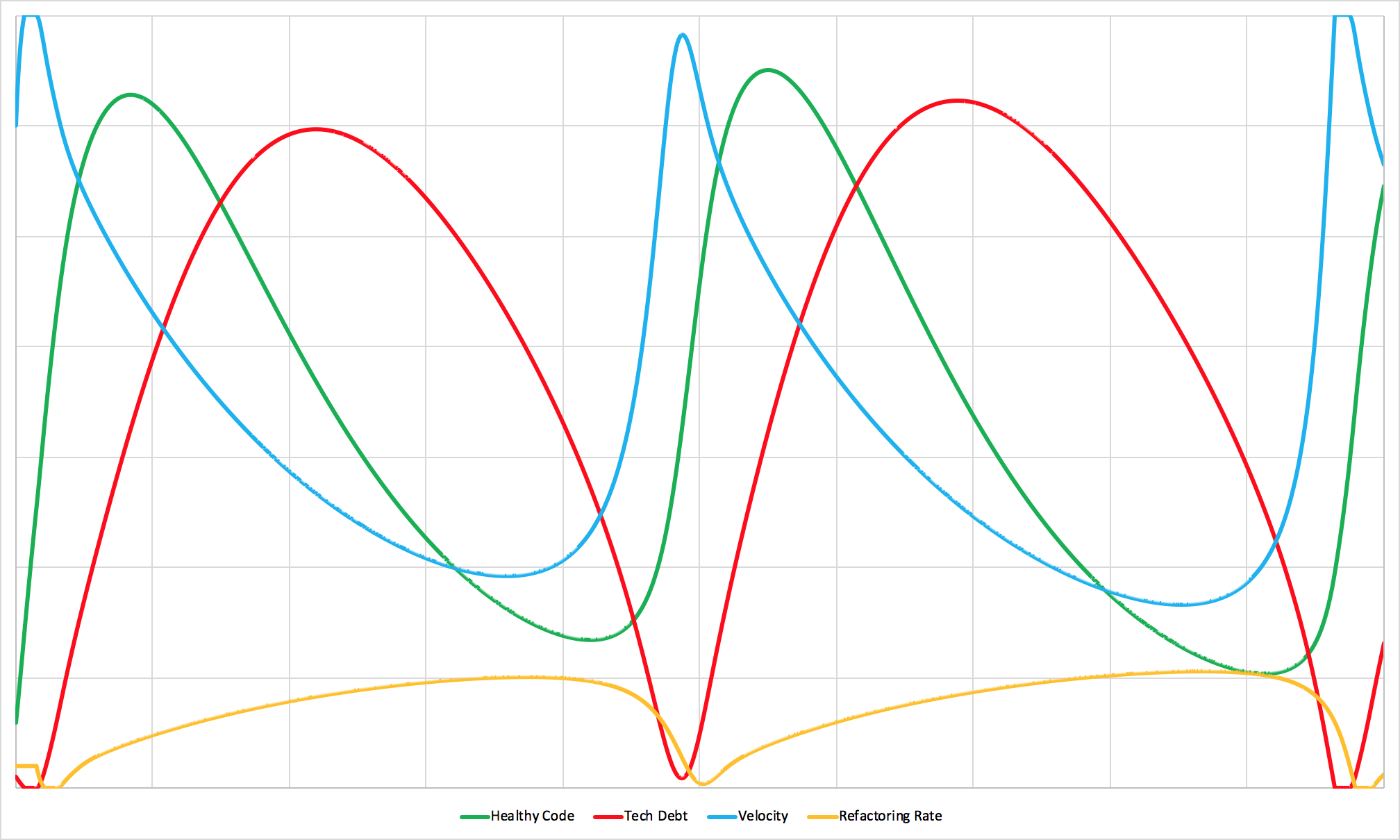
When feedback loops have lag.
Up until this point, the model has assumed that teams can adjust the amount of time they spend refactoring in real-time as conditions change. It’s a useful abstraction that makes the system easier to understand, but it doesn’t reflect reality.
Real teams have momentum, existing commitments, sprint plans, and organizational politics to navigate. There’s almost always a delay between recognizing that a codebase is becoming problematic and actually starting work to address the underlying issues.
Even small delays in feedback loops can create surprisingly wild swings in team behavior. You see periods of over-investment in new features followed by periods of under-investment. Shipping sprees followed by refactoring marathons. The team’s velocity becomes erratic and practically impossible to predict.
Larger delays make these swings even more extreme and unpredictable.
Perfect real-time adjustment probably isn’t realistic for most teams. But multi-month delays between recognizing problems and being able to respond to them? That’s often a choice, and it’s one that makes everything significantly harder to manage.
Counterintuitively, giving teams the authority to pull the emergency brake and address technical debt when they recognize it can actually make the system more stable, more predictable, and more able to consistently release new features, not less so.
The refactoring trap
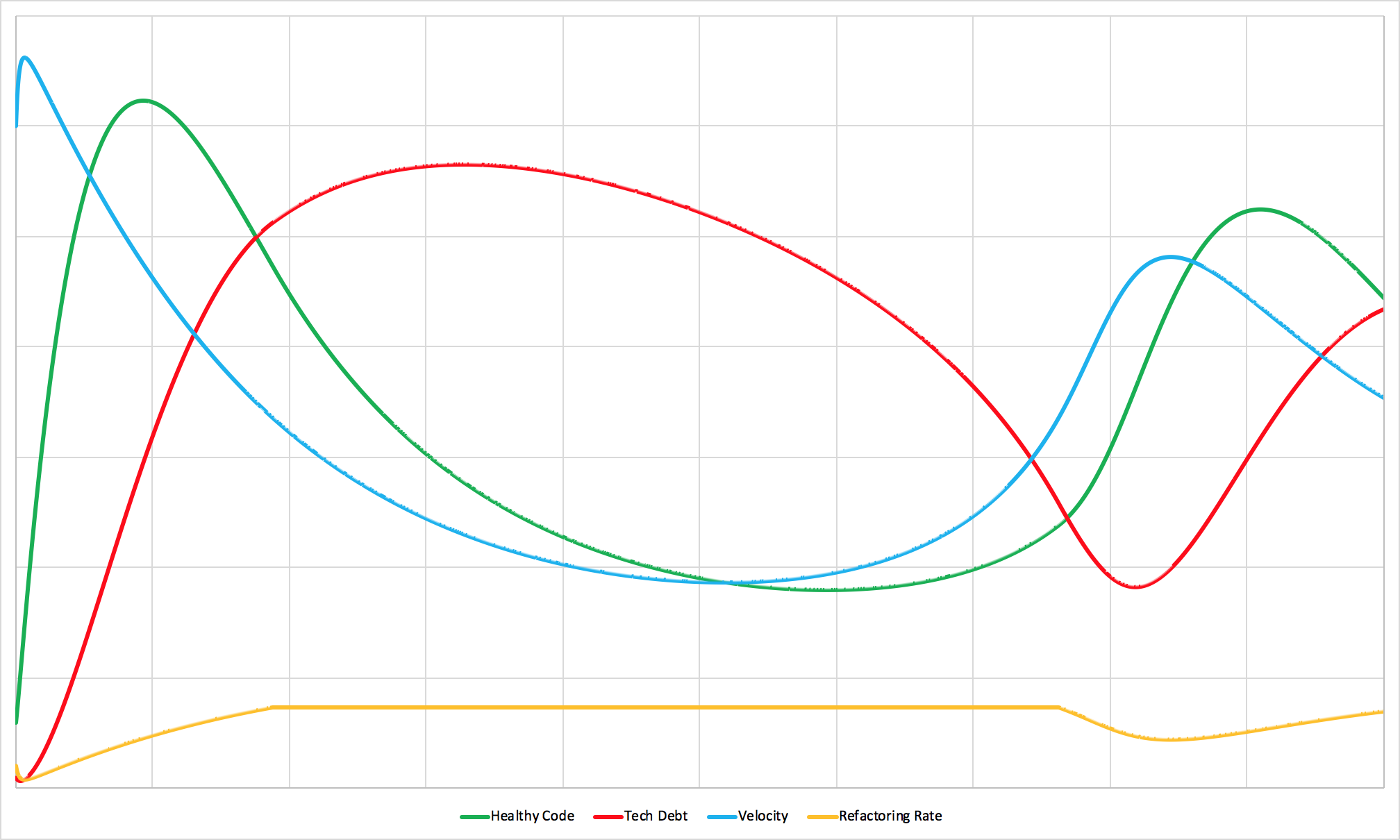
What happens when you cap refactoring time.
“Don’t spend more than 20% of your time refactoring.” For executives, marketing departments, salespeople, and others whose success depends on having new features to announce, these policies can be very appealing. After all, customers want new functionality, not invisible improvements to code they’ll never see.
But these seemingly reasonable constraints can have devastating long-term consequences for both productivity and the team’s ability to deliver new features consistently.
When you look at the simulation, even relatively weak restrictions on refactoring time create dramatic effects on system behavior. When technical debt accumulates to the point where it triggers the refactoring limit, teams find themselves unable to address the underlying problems effectively. Instead of taking the short-term hit to new feature development and getting the debt under control, they’re forced to chip away at it slowly while their velocity remains depressed.
Eventually, after spending a disproportionate amount of time working in an increasingly difficult environment, they make enough progress to shift focus back to new development. But here’s the problem: each cycle through this pattern leaves the codebase in worse shape than before. The average level of code health drops over time, and the team spends an increasing percentage of their effort just fighting against the tide of legacy code they’re trying to improve.
If you push this dynamic further and restrict refactoring time even more aggressively, you can watch the system collapse entirely:
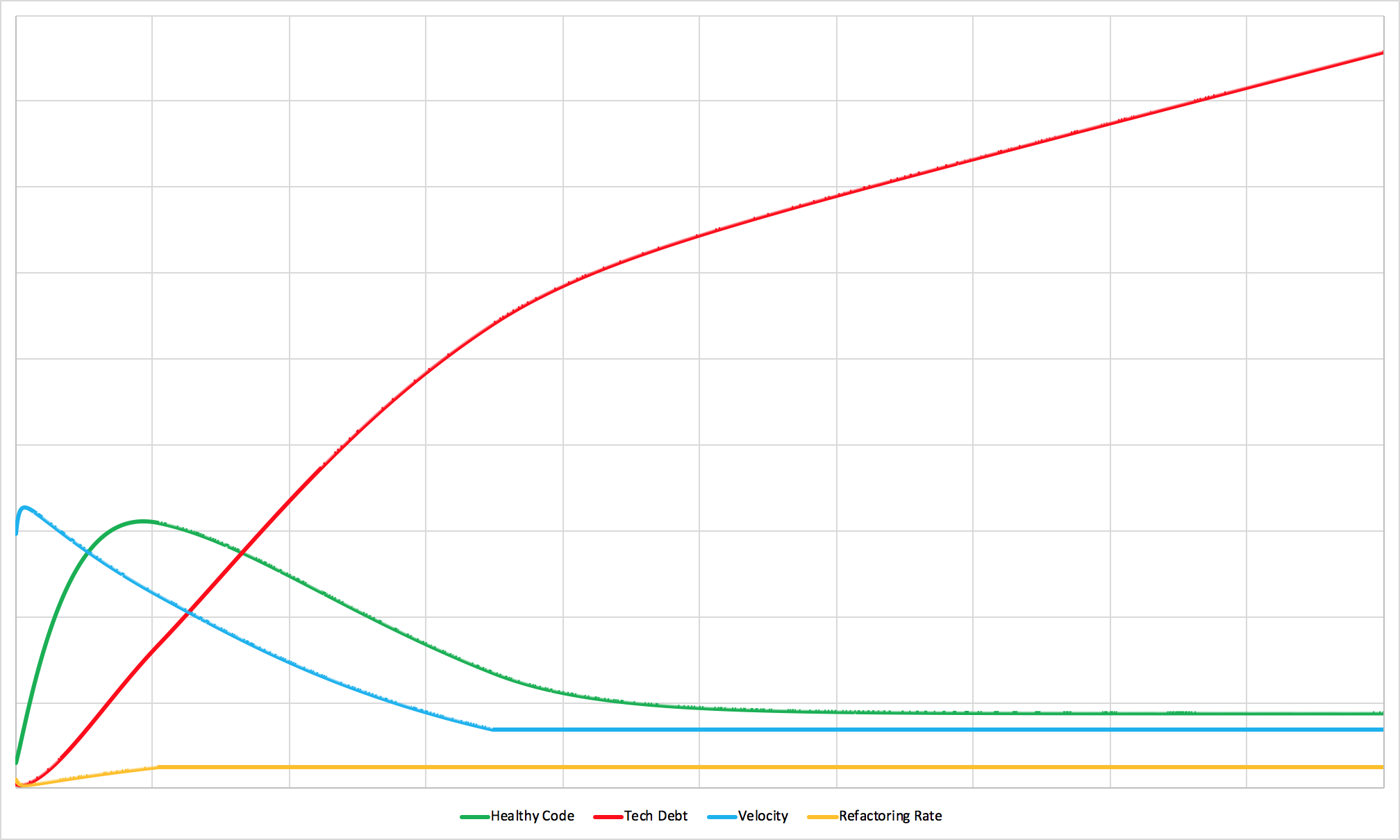
When good intentions create system failure.
Tech debt grows faster than it’s paid down. Features crawl. Without the artificial velocity floor (hiring to replace quitting engineers), output would hit zero.
This is the organizational equivalent of overfishing to extinction. Not the goal, obviously. But the predictable result.
Sometimes you just have to bite the bullet and take care of the code (before it takes care of you).
The complex reality
The scenarios we’ve explored so far have the convenience of showing only one variable changing at a time. In the real world, of course, things are never so neatly isolated.
Real software teams operate within much more complex systems. They face external shocks like economic downturns, regulatory changes, and competitive pressures. They interact with other parts of the organization - HR, Legal, financial constraints, marketing needs. When you remove the convenient simplifications that make these models easy to understand, the complexity can seem overwhelming.
But here’s what’s great about the system dynamics approach to these issues: even when you add back all that messy complexity, the core patterns remain surprisingly consistent. Healthy teams still naturally cycle between periods of shipping new features and periods of addressing technical debt. Delays in feedback loops still create instability and unpredictable behavior. Investing in refactoring still pays long-term dividends, even when the math gets complicated by other factors.
The fundamental principles here hold true even when the details get much messier than our simple models suggest.
A different way forward
Picture your next planning meeting, but imagine it working completely differently than usual.
Instead of the typical arguments about story point estimates, your team builds scenarios and models outcomes. Instead of debating which “best practice” to follow, you examine the actual feedback loops in your system. Instead of making demands based on intuition, you explore the likely consequences of different approaches together.
Imagine technologists and business people sitting in the same room, having genuinely rational conversations about the real tradeoffs they face. Questions about speed versus quality become discussions around graphs and data, not ideological battles. Decisions about technical debt versus new features become collaborative exploration of simulated outcomes, not political struggles where the loudest voice wins.
I’ve seen teams work this way, and they accomplish extraordinary things. They make better decisions faster. They waste less time on unproductive arguments. Most importantly, they build trust across functional boundaries that seemed impossible to bridge.
The biggest barrier to this kind of collaboration isn’t lack of motivation or goodwill. Most people genuinely want to understand each other and make reasonable decisions together. The barrier is language. When people can’t effectively communicate the consequences of their requests, or when they can’t explain the reasoning behind their recommendations to pause new development and refactor a key function, there’s simply no way to find common ground.
What we need is a shared vocabulary that allows us to talk with each other instead of past each other.
System dynamics isn’t a complete solution to this communication challenge, of course, but it’s a powerful place to start. It anchors technical discussions in something more concrete than personal opinion but less dogmatic than industry best practices. It gives teams a way to make abstract tradeoffs visible and testable.
Some of the best technical discussions I’ve ever been part of started with simple simulations like the ones we’ve explored here.
But don’t take my word for it.
Try building a simple model of your own team’s dynamics. Run a few scenarios. See what patterns emerge and what insights surface.
It might be exactly the tool you need to help your team move forward together.